Overview of Indexing
Broadly, an index is a structured system of signs. The indexing process is one of associating clearly and accurately a set of signs with objects or referents. The purpose of indexing is to provide a tool for accessing a defined set of objects. Objects accessed through an index are content. Turning objects into content enables use in further processes. Strategically, indexing is the application of a critical apparatus to content-objects.
The tasks required to implement an indexing strategy include:
- Define a set or sets of signs relevant to the use case for the content-objects;
- Determine an organizational standard that defines the method for using resulting tool;
- Establish conventions for binding the signs to the content-objects to enable retrieval;
- Associate signs to content by applying retrieval conventions
Context and use case determine the approach, standards, and technologies appropriate to an indexing effort.
Goals of Indexing
There are eight fundamental goals for indexes:
- To facilitate reference to specific items
- To accommodate diversity content-object structure
- To disclose relationships
- To disclose omissions
- To enable discovery
- To facilitate serendipity
- To provide a nomenclature standard
- To provide a content-domain map
[Adapted from Borko and Bernier, Indexing Concepts and Methods, 1978]
There context may affect emphasis, these goals are as valid for economic objects as they are for Search Engine Optimization (SEO) as they are for hardbound books.
Quality in Indexing
The abstract definition of index quality is how well the formula "Is 'this' about 'that'?"is answered. This results-based formula relies on the definition of an index as a tool, a tool for find something. As such indexing is integral to implementing a search strategy, in which the goal is a identify a set of objects the elements of which satisfy the requirement of being about the topic. The requirement being aboutis elastic to some extent. The extent to which it is flexible determines how the definition of retrievable units is applied to instances of content-objects. At the same time, the criteria of "aboutness" asserts that not every object satisfies the condition "is content" or "has meaning." The definition of "meaning" is based on the core use case for which the tool has been developed. Discriminating "is-ness" and "about-ness" is a core issue in indexing, and an import aspect of its value-add proposition.
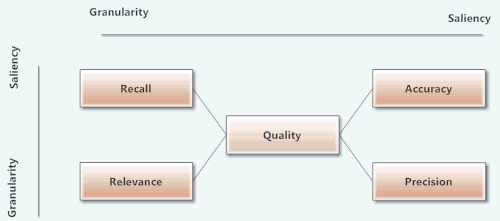
Pragmatically, index quality is a function of the matrix of four result set measures:
- Accuracy
- Precision
- Relevance
- Recall
Two contextual standards are needed to evaluate quality in terms of this matrix:
- Unit of retrieval for determining the level of granularity
- Persona-based use cases for prescribing saliency
Many factors affect quality, some of which occasionally serve as rough-and-ready quality standards. These factors include standards such as number of terms applied, placement of locators, and number of occurrences prior needed for addition to the critical apparatus.

Approaches to indexing depend upon the technology environment, characterizes of content-bearing units, use cases, quality standards, and the utility/cost ratio used in defining the value of the endeavor.
To provide a flavoring of indexing methods, consider the following short list:
- Semantic technology rooted in Linked Data-RDF is emerging in content domains involving data access and visualization as well those with high-value technical information in which extraction in an "as if" single-source repository scenario is critical. A potential growth area for this type of indexing is as a data virtualization strategy or as a successor to large-scale Master Data Management implementations.
- Auto-classification and mining technologies (of which there are several) for textual materials are appropriate in many contexts. Of course, not every auto-classification approach is appropriate to every context (Google works moderately well for the Internet but not within an Enterprise).
- Machine-aided human indexing (another complex topic) has demonstrated value in many contexts including submission to content management systems, high-volume medical office coding, and indexing of high-volume, high-value technical literature.
- Human-based indexing remains an important strategy for a wide range of content-objects that continue as automation challenges, such as images and other media records, non-digital textual records, and low-volume, high-value print publications such as books and manuals requiring the find of very precise information.